How to master identity resolution in a warehouse-native world

For data-driven marketing teams, a unified customer view is the holy grail for personalization — critical for driving higher conversion rates, great customer experiences and higher lifetime value.
As companies mature with their data platforms (and ingestion becomes easier), leveraging the existing data assets in data warehouses becomes more valuable, creates stronger foundations and enables richer insights and activation.
However, getting a good view of your customers (even at a 101 level) requires more than just bringing data into your cloud platform — even if some composable CDP providers suggest it’s a foregone conclusion. This is where identity resolution comes into play.
What is identity resolution?
Identity resolution (IDR) solves the problem of uniquely identifying your customers at an individual level and tying all of their behaviors and associated data together. This allows you to personalize product recommendations, create truly omnichannel experiences, reduce potential churn and increase customer lifetime value.
A few examples:
How would you identify a customer who frequently visits your website but has never bought anything (and doesn’t log in) to send them a personalized offer?
What if you could tie together your website, sales tools and mobile app to send in-app notifications related to website browning activity?
What would the added value be for sending subscription offers to incentivize highly engaged customers?
Despite the importance of good identity resolution, the biggest challenge for companies using their data warehouse for customer insights is still identifying and unifying customer data to activate it effectively. This hinders their ability to improve customer segmentation, enhance personalization, reduce churn and measure customer lifetime value.
Capabilities needed for effective identity resolution
Before we dive into some of the options, let’s start with a mutual understanding of the capabilities you may need for effective identity resolution:
Data infrastructure and ingestion
Data must be seamlessly imported from various sources into your data warehouse (DWH). We’ll assume you’re already here or have the tools to do this between your existing cloud, an iPaaS and/or a modern ETL tool.
If you’re more advanced, you may consider even more advanced capabilities here with tools like Metarouter or Snowplow to bring in customer data in real-time.
Deterministic matching
The ability to match records based on exact identifiers like email addresses. This is the bare minimum of a “rules-based” identity resolution approach.
Probabilistic matching
A rules-based approach won’t work when your customer data isn’t very clean or organized or if you’re pulling in a larger number of identifiers. You’ll likely need to use statistical methods to link records with a high likelihood of belonging to the same customer.
Depending on your use case and your need for accuracy, you’ll probably want to think through the certainty level of your probabilistic approach to matching leverages. How much are you willing and able to tolerate potential mismatches and how do you handle them?
Identity graph
As your data gets more complex, an identity graph, which creates a structure to represent all of the potential customer identifiers (e.g., emails, phone numbers, user IDs, device IDs, cookie IDs and more), will likely be needed to ensure that you’re capturing a full view of your customers and all of their touchpoints.
A persistent ID
As the number of systems you integrate between the web, CRM, marketing tools, social media, mobile apps, etc., increases, the number of identifiers you have will increase as well.
Creating or leveraging a provided persistent ID will help ensure you’re looking at customers consistently across channels.
Reference data and enrichment
Assuming your data is in the cloud, you likely have access to a data marketplace offering datasets from a wealth of providers that will enable you to enrich customer profiles with additional data points for a more complete picture.
Manual intervention
Even with this capability, it is still critically important to view the results of an identity resolution process and make adjustments where needed to prevent mismatches or accidental exclusions.
An overview of identity resolution providers
The options in the market are confusing, and not all will work the same way. Providers have different approaches to addressing the challenge of unifying and identifying customer data. Below are key solutions and players in the market.
Big cloud ‘entity frameworks’
Cloud providers like Google Cloud and AWS offer built-in entity resolution frameworks within their cloud platform, but calling them “identity resolution” is disingenuous at best.
Think of them as providing the foundational toolkit to either DIY a solution or share your data with an identity spline like LiveRamp or Experian (who still manually runs their own match and merge and sends it back to you, often taking days).
Dig deeper: Cloud data warehouses set to disrupt the martech stack
Composable CDPs
Some warehouse-native CDPs and data activation tools, like Hightouch and Rudderstack (and soon Census and possibly Amperity), are starting to meet the moment by offering (often limited) warehouse-native identity resolution capabilities.
Currently, they are largely focused on match and merge processes or deduplication. They may struggle to handle unknown to known conversions or work with identifiers like cookie IDs, IP addresses or device IDs, making personalization trickier for unidentified website visitors.
They also won’t create a unique identifier you can use and propagate across systems, making validating identities across channels or domains more difficult.
Enterprise MDM solutions
Tamr, Reltio and Informatica offer comprehensive master data management (MDM) solutions that excel at identity resolution. However, they come with a rather hefty price tag, as they are designed for more robust MDM needs and often handle the higher level of computing (which your price needs to cover).
We’re hearing rumblings, though, that this may start to change as they adapt to changing market needs by offering focused solutions for a single domain (customer). This will be an interesting space to watch in the coming months.
Open-source options
To fill the gap, open-source players like Zingg, Senzing and Splink are offering libraries that support entity resolution capabilities. While they can be quite powerful, they require a fair amount of technical proficiency to deploy and manage.
They don’t really have the user-friendliness (yet) to be able to be self-managed. They’re also currently designed as brute-force ML algorithms that will require a fair amount of input to get your desired results.
Identity spines
Also known as vendor identity graphs, identity spines are organizations that have a database of U.S.-based consumers and collect identifiers, signals and attributes associated with specific consumer identities within their database.
They typically integrate with a CDP or MDM solution but are now available through data marketplaces, and they still offer fully managed services. When you need a full customer profile, they can be valuable but expensive. Although many other options (MDMs, CDPs) offer cost-effective integrations for spines.
Packaged and hybrid CDPs
I know we’re talking about warehouse-native approaches here, but don’t discount the possibility that a packaged CDP still might be a very relevant solution.
If you’re light on data engineering skills or your data warehouse team isn’t quite ready for prime time, you should still consider using a CDP with a strong identity capability to enrich your customer data from your data warehouse and (some of our customers have been fond of solutions like ActionIQ, BlueConic, Amplitude, Lytics and Segment that can do this at a relatively low cost).
RepresentativePlayersStrengthsWeaknessesBig Cloud “Entity Frameworks”GoogleAWSSnowflakeDatabricksProvide the tools for a DIY approach or faster third-party management.Provide the tools for a DIY approach or for faster third-party management.“Composable” CDPsHightouchCensusRudderstackGrowthloopMay offer basic deduplication and fuzzy matching capabilities.Data prep, building a graph and creating a persistent ID are still your responsibility.Enterprise MDM SolutionsReltioTamrAqferHigh precision, good user interfaces, loved by regulated industriesCan be costly and spines and IDs may be added on packages.Open Source ToolsZinggDedupeSplinkRecordLinkageCan easily handle deduplication, fuzzy matching and ML-based matching.Potentially high compute and open-source versions may have complex implementation (although Zingg has a managed service).ID SpinesTransUnionMerkuryExperianLiveRampEnable you to house all your data and offer data sharing capabilities.Matching back to your private graph may still be an add-on service — assuming your graph is ready.Hybrid and Packaged CDPsActionIQBlueConicAmplitudeSegmentAmperityLyticsSimplify some of the complexities of the other options into a fully managed platform.May not offer identity as a stand-alone capability and may be more complex to implement.A summary of the options claiming to offer some or all entity resolution/identity resolution capabilities.
Dig deeper: Should you use your data warehouse as your CDP?
If all of these solutions don’t quite meet the mark on their own, what would?
When thinking about ID resolution in data warehouses, remember that you’re shifting from a “software buying” mentality to a “build and maintain a solution” mentality. Building a village within your organization is critical to success.
The reality is that you’ll likely need a combination of solutions to meet your needs and get to a robust set of capabilities, but here’s what we’re hearing from our customers on capabilities they’re looking for:
Leverages your existing cloud infrastructure for scalability and manages and scales automatically.
Manages and adjusts the build of your private identity graph.
Employs a user-friendly interface for setting rules, adjusting risk parameters, visualizing results and training the model.
Offers affordable pricing that scales as your customer base grows.
Creates and manages a persistent ID that can be pushed back to your data warehouse and downstream systems for activation.
Provides cost-effective enrichment-as-a-service options to augment your data where needed.
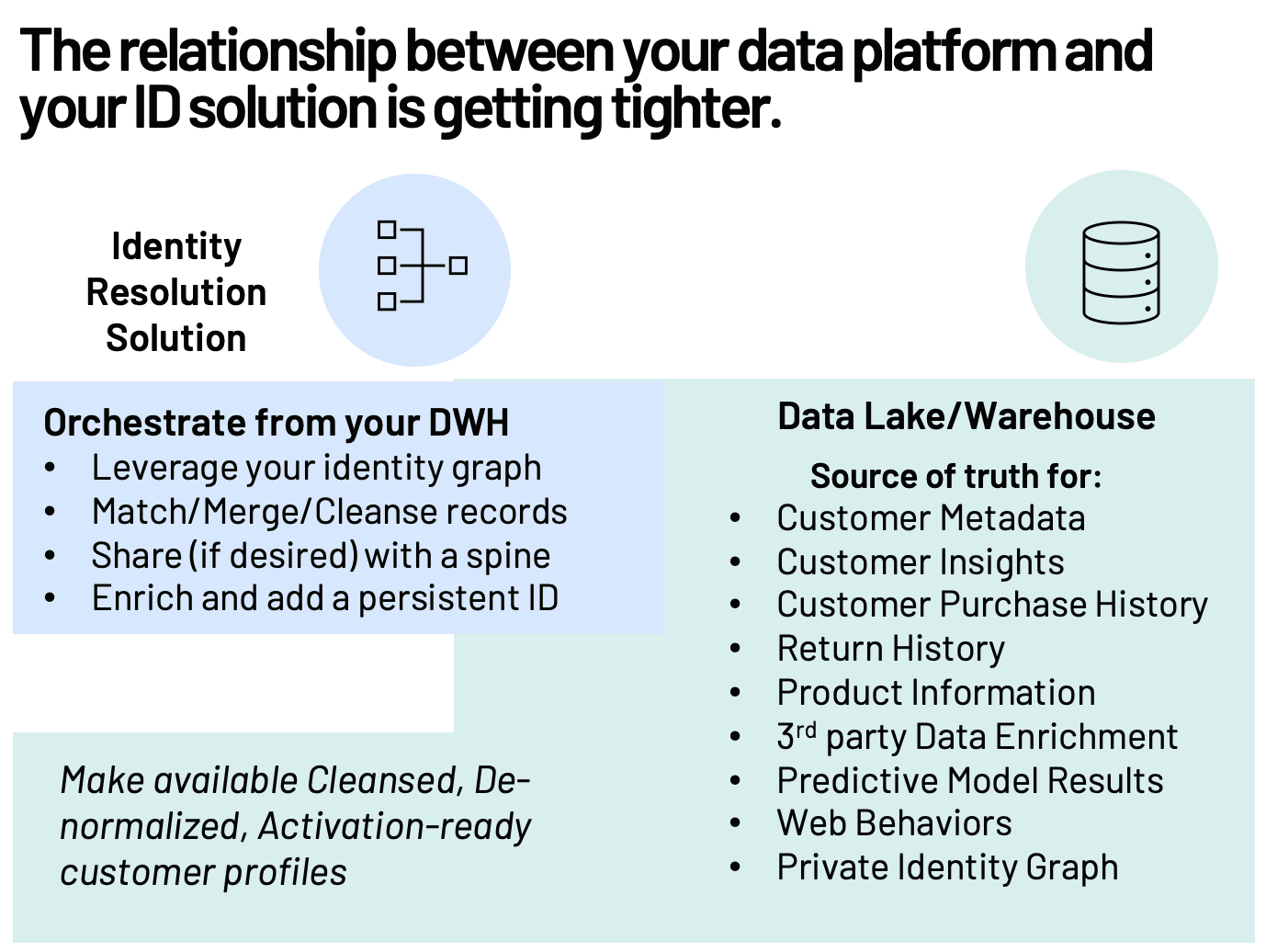 In a warehouse-centric architecture, you’ll likely still need a solution specific to your specific ID resolution needs. Here is an example of how those capabilities may come together based on a recent Actable customer.
In a warehouse-centric architecture, you’ll likely still need a solution specific to your specific ID resolution needs. Here is an example of how those capabilities may come together based on a recent Actable customer. Getting started with identity resolution
Start by identifying your core IDR needs. Here are some initial steps we typically take:
Define your use cases: What specific business problems are you trying to solve? Will identity resolution be necessary to address the specific challenge? To what extent?
Assess your data landscape: Identify the type and volume of data you need to unify. It’s probably worth spending some time working in a data visualization tool like Tableau or Power BI to profile, understand and map some of the nuances of your customer data and where you need to find a solution to bring things together.
Evaluate existing tools: Explore the IDR capabilities of your martech stack and the technical capabilities of your team to manage additional solutions. There is a high probability that you may already have some pieces in place to get to a minimum viable solution for meeting your immediate needs.
Get help when needed: Don’t hesitate to seek help from experienced martech consultants for guidance and implementation.
By following these steps and choosing the right IDR solution, you can start down the path of unlocking a unified customer view and driving significant business growth — but don’t stop there. Much like your customer base, your identity strategy should continue to evolve and grow with you.
Email:
Business email address
Sign up now
Processing…
See terms.
The post How to master identity resolution in a warehouse-native world appeared first on MarTech.




